Data De-Identification
Data Analytics and AI
The ability to analyze data effectively has become more powerful than ever before. AI-driven data analytics can unlock insights that drive innovation and improve outcomes. However, this data still needs to be protected, especially when dealing with sensitive information that could compromise individual privacy. Balancing the promise of AI with the need to protect privacy is a critical challenge. This is where data de-identification becomes essential—allowing organizations to leverage AI's potential while ensuring personal data remains secure and anonymous.
De-Identifying Data
AI services have great capabilities that can increase the quality and efficiency of data analytics. However, data analytics often deals with sensitive data that should not be shared without an appropriate privacy agreement in place. Because of this concern, data can be de-identified so that private data is not exposed with an AI service while still leveraging the strengths that the AI service has.
Personal Data
Personal data is any information related to an identifiable person. Personal data includes a wide variety of direct identifiers, as well as indirect identifiers.
Direct Identifiers vs Indirect Identifiers
Direct identifiers are anything that can directly identify an individual (full name, social security number, etc). Indirect identifiers are identifiers that do not identify an individual on their own, but can be used alongside other identifiers to identify an individual (race, ethnicity, age, zip code, birthday, etc). Both direct and indirect identifiers should not be present in data that is being shared with an AI service.
De-Identified Data vs Anonymized Data
Within the privacy world, it is important to note the difference between de-identified and anonymized data. De-identified data is NOT the same as anonymized data, and should never be displayed or marketed as such. Anonymized data can only be claimed as such when the entirety of the data across an organization does not have any direct or indirect identifiers that could lead to the identity of any person.
Types of Analyses
Once data has been de-identified, there are many types of analyses that can be performed in order to draw conclusions from the data. Common types of analyses used across different career fields are listed below:
- Market Basket Analysis
- Determining which products users frequently purchase together.
- Market Trend Analysis
- Identifying trends in a given market to anticipate demand and adapt strategies.
- Campaign Performance Analysis
- Evaluating success of marketing campaigns in terms of conversions, engagement, or recruitments.
- Sentiment Analysis
- Analyzing customer or employee feedback, reviews, or engagement to understand how they feel about the brand, product, or service.
- Cost-Benefit Analysis
- Comparing costs to the benefit of an action or decision.
- Sales or Usage Forecasting
- Predicting future sales or usage based on historical data and market conditions.
- Process Efficiency Analysis
- Examining workflows to identify bottlenecks or areas of improvement.
- Survey Analysis
- Drawing insights from customer preferences in order to direct areas of improvement or focus.
De-identification Checklist
This checklist should be used before inputting any BYU data into an AI platform.
1. Determine goal of data analysis or processing
2. Review goal with privacy principles in mind
3. Determine direct and indirect identifiers in the data set
4. Determine minimal acceptable data utility
5. Select a de-identification method (see below)
6. Evaluate risk of re-identification (which refers to the process of reversing the de-identification of data, thereby linking previously anonymized information back to specific individuals)
7. Import sample data to test data transformation
8. Evaluate usability of data output
9. Refine as necessary and apply data transformations to entire data set.
10. Export transformed data as use as intended.
Methods for data de-identification
Note: Below are summaries of each data de-identification method. Please ensure you thoroughly understand any given method before using it with data.
There are many ways to de-identify data. Certain methods work better with certain kinds of data, and becoming familiar with what methods work best with certain data sets is a great way to leverage the amazing capabilities of AI while still adhering to BYU's privacy policies.
Note: It is important to recognize that using de-identification does not remove all risk related to processing personal data, but instead greatly reduces the risk when completed effectively.
Omission and Sub-Sampling
Omission is the simplest method of data de-identification. Omission is the practice of not including indirect or direct identifiers in the data set. Sub-sampling is the method of refining an entire data set to just a sample of the set which will be shared with the AI model, reducing the probability of reidentification.
Suppression
Suppression is another basic method of data de-identification and includes removing any values or columns from the data in an effort to reduce the risk of reidentification. Suppression includes removing quasi-identifiers, which are identifiers that do not uniquely identify an individual in most cases but can in some cases be used when combined with other quasi-identifiers (ex. job title is not a quasi-identifier unless it is a unique job and the company information is also present in the data set).

Generalization
Generalization is the method of broadening the data set to reduce the direct link to individuals. This can be accomplished by reporting values as ranges instead of unique values (ex. the zip code 84057 could be generalized to the category 84000-84500). Generalization can be applied to entire data sets or just specific records as needed.

Swapping
Swapping is a more complicated method of data de-identification and includes exchanging values between records, within defined levels of generalization (ex. you could exchange the hometown of two individuals if you were studying correlation between age and county of residence). Swapping should be handled with care to ensure that results of the data set are correct and authentic.

Random Noise Addition
Random noise addition is the process of adding random data or columns to the data set in order for the data to no longer match any individual person. Another way of completing random noise addition is to add or remove random amounts to unimportant numeric data, in an attempt to further hide the identifying characteristics of the individual. Random noise addition can also be done by replacing certain values with other values in a manner that is consistent throughout the data set (ex. ages 18-21 are given category A, 22-26 are category B, etc).

Aggregation
Aggregation is the process of taking individual data sets and combining them in order to analyze trends while protecting individual privacy by using groups of individuals with similar characteristics rather than isolating one individual at a time. A key to aggregation is examining what groupings of individuals will be effective to meet analytical goals.

Redaction
Redaction erases or masks identifiers in all data records, using techniques like pixelation or black out.

Pseudonymization
Pseudonymization is the process of transforming names and other information with pseudonyms in the data (ex. individual (with a real name of Cougar) was given the pseudonym "r543c" and voted yes on the poll). Pseudonymization can be difficult as a balance needs to be struck between risk and usefulness of the data.

Hashing
Hashing is a mathematical algorithm that transforms a list of characters into a new value that represents the original list of characters (ex. Payment method ending in 1234 becomes hash akd427).
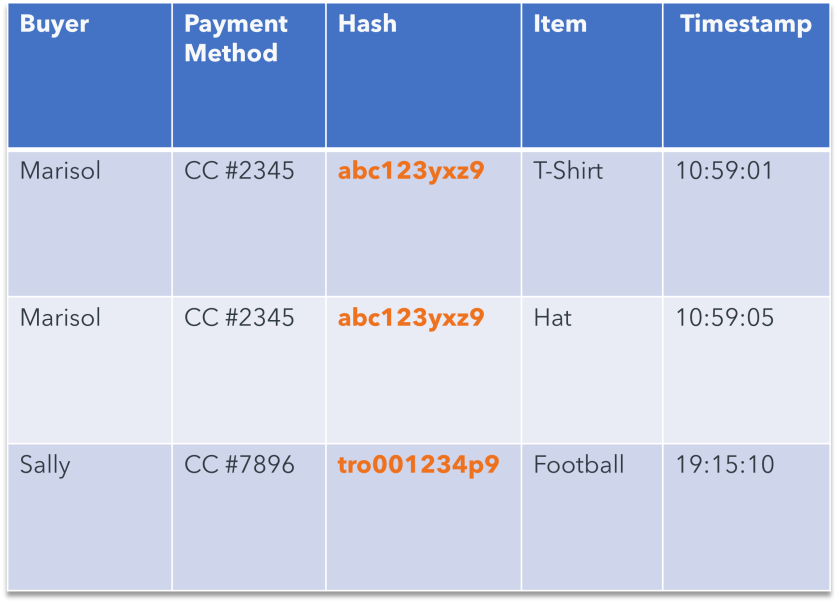
Tokenization
Tokenization is a process of substituting a piece of sensitive data with a non-sensitive substitute called a token. Tokens can be created via hashing, a randomly generated identifier, etc.

Encryption
Encryption is a process of scrambling information so it can only be read by someone with the "key" to unscramble the information (ex. This is very commonly used to display only the last four digits of a social security number).
For questions or concerns about data de-identification, please reach out to the AI Committee at ai-committee@byu.edu.

Personal Data: Any information related to an identifiable person. Personal data includes a wide variety of direct identifiers, as well as indirect identifiers.
Direct Identifiers: Any information that can directly identify an individual (full name, social security number, etc)
Indirect identifiers: Identifiers that do not identify an individual on their own, but can be used alongside other identifiers to identify an individual (race, ethnicity, age, zip code, birthday, etc)
De-identified data: Data set that has undergone a data de-identification method in order to remove or hide all direct and indirect identifiers.
Quasi-identifiers: Identifiers that do not uniquely identify an individual in most cases but can in some cases be used when combined with other quasi-identifiers (ex. job title is not a quasi-identifier unless it is a unique job and the company information is also present in the data set)
Re-identification: The process of reversing the de-identification of data, thereby linking previously anonymized information back to specific individuals